微信读书 H5 基础库建设总结
前言
去年 8 月份开始接手微信读书 H5 的相关开发工作,算是正式入职以来的第二个任务。初次踏入移动端开发领域,我是以自信满满的姿态去迎接它的。然而,没多久我就被事实狠狠地打脸了。不禁感叹,曾经以为是净土一片,到头来果然还是深坑一堆,摔个伤痕累累。所幸,抗争的最后也不是一无所获,造了个轮子,在此总结一番,希望能对大家有所帮助。
发现问题
接手读书时已经有几个上线的页面了。初步扫了下代码,比较明显的问题就是代码冗余:不同的页面存在着大量的相同代码块。设置微信分享标题、检测读书是否安装等相似的代码几乎每个页面都嵌入了一份。外部库共引入了两个,Emoticon 表情转换库和 Zepto。Emoticon 支持表情及语言数量多的特性使得源代码里面包含了大量读书并不需要的数据。Zepto 的问题更为严重,页面上其实只用到了一个 ajax 方法,完全没有必要将整个库引入页面。
初步解决
Emoticon 的文件大小很好解决,下载源码,将不需要的东西通通删掉,体积立马少了几倍。Zepto 也直接干掉,重新编写单个 Ajax 方法进行替换。公用函数复用也不是问题,建立一个 weread.js 文件,将共用的函数都往里面丢,然后再在所有页面引入这个文件,它大概长成下面这个样子:
var weread = window.weread = (function (exports)
{
exports.version = '0.0.1';
return exports;
})({});
(function ()
{
var util = {};
util.methodA = function () { /*...*/ };
util.methodB = function () { /*...*/ };
// ...
weread.util = util;
weread.module = function (name, requires, module) { /*...*/ };
weread.use = function (requires, module) { /*...*/ };
weread.extend = function (name, requires, module) { /*...*/ };
})();
weread.extend('util', function (exports)
{
exports.methodX = function () { /*...*/ };
// ...
});
weread.module('dom', function () { /*...*/ });
weread.module('ajax', function () { /*...*/ });
// ...刚写完看起来相当不错,除了 ajax,util 模块外,我还仿照 jQuery 的 api 简单写了个 dom 操作模块。为了使用方便,我还自作聪明地把 angular 的 Denpendency Injection 实现方式给抄了过来(其实就是通过扫函数名注入相应的模块,后面遇到代码压缩就傻了,只能乖乖换回 amd 的依赖声明格式)。
基础库模块化
随着读书开发工作的进行,weread.js 文件体积开始膨胀。当代码快接近千行大关时,有件事不得不开始着手进行了:基础库模块的拆分工作。
方式一:
将 weread.js 拆分成多个文件,用多个 script 标签将其引入页面。然而需要编写构建任务合并文件,替换 script 标签为单个,减少 HTTP 请求数,而且拆分的文件数量一多,成堆的 script 标签将成为恶梦。改进下,用 LABjs 换掉script 标签的编写,没有多大实质性改变,合并文件因此变得更加困难,还要多引一个库。
方式二:
使用 seajs,requirejs 来进行模块化,看起来好像不错,目前很多人都是这么干。问题是,我还是要在页面上引多一个库,我还是需要对文件进行合并来减少 HTTP 请求。requirejs 需要用 r.js 合并,seajs 可以使用 combo,但需要在页面上引入一个文件名映射表,因为文件名都被打上版本号了。当然,我最不喜欢的是写每个文件的时候都要包上一层define('xxx', [], function() { /*...*/ });。
方式三:
Browserify, Rollupjs 和 Webpack 等线下模块化打包工具。Browserity 可以用写 node 的方式来编写模块,很不错。Webpack 更好,可以通过 loader 来 require everything。Rollupjs 有一点比另外两个出色,它可以只引入文件中自己所需要的代码,前提是你使用 es6 的 import 和 export。遗憾的是,使用这些库都有一个前提条件:你的页面要有一个入口文件。读书页面的业务逻辑非常简单,利用封装好的底层库和通用组件,基本上可以做到将页面逻辑代码控制在两百行以下。这种情况为了简便完全可以将其跟 html 文件写在一起,将 Node 端模板引擎的相关语句嵌入到代码中去,还可以减少一个 HTTP 请求。换句话说,我想要的是下面的这种代码编写方式:
<!-- PageA.tpl -->
<div>
A bunch of html elements, blah blah blah...
</div>
<script>
a.on('click', function ()
{
{{if env == 'xxx'}}
doSomething();
{{else}}
doSomethingElse();
{{/if}}
// ...
});
</script>使用上述工具并不支持这种写法,看起来也很难将它们改造成支持这种写法的样子。使用 Browserify 和 Webpack 也容易出滥用 npm 包, loader 的问题,导致打包后的文件体积过大,根本不适合采用在移动端。关于这点,可以参考RAIL: Putting the User at the Center of Performance with Paul Irish里面 Reddit 移动端的例子。
综合来看,我好像需要开始自己造一个适合读书这种情况使用的轮子了:一个小型的模块化打包工具。
造轮子
明确需求
在造轮子之前,我有必要先理清下自己想要的到底是什么东西,简单列了以下几点:
- 它可以将我的多个模块合并成一个文件,并且是实时 watch。
- 模块间并不是相互独立,需要有一种方式来声明依赖,最大限度做到代码复用。
- 使用非常简单,只需要在页面上直接调用即可。
- 生成的代码在 Node 端也可以使用,所以必须支持 commonjs 和 es6 的模块调用方式。
这里基本就想像出来我需要做到的应该是什么样的效果,流程大概如下:
- 为一个公用的小模块 A 新建文件,声明依赖,编写代码。
- 新建 html 文件,运行打包工具,在里面直接调用
_.A(1, 2)。 - 打包工具生成 util.js,暴露全局变量_,里面包含了 A 模块。
- 直接引入 util.js,浏览页面,一切运行正常!
- 如果需要使用其它公用函数,在页面中直接调用
_.xxx()。
总结下,我需要的是一个命令行工具,它能扫描代码实时生成类似于 underscore 的 util 库。
开始动手
首先要搞清楚的是最终生成的文件的样子,我预想中的应该是下面这个样子:
(function(root, factory)
{
// Umd规范,应该是可以自由控制由不同规范包裹函数体的。
if (typeof define === 'function' && define.amd)
{
define([], factory);
} else if (typeof module === 'object' && module.exports)
{
module.exports = factory();
} else { root._ = factory() }
}(this, function ()
{
var _ = {};
_.A = (function () {
/*...*/
})();
_.B = (function () {
/*...*/
})();
return _;
}));扫描代码需要支持 namespace.xxx,require('./util') 和 import {xxx, xxx} from './util' 的几种调用方式,几个正则表达式搞定。模块间的依赖关系稍微棘手一点,我们在页面中调用了 B 方法,B 方法依赖于 A 方法,那么 A 方法就必须在 B 方法调用它之前使用。换个说法,就是生成后的代码文件 A 方法必须在 B 方法之前。按照 Webpack 的做法,先把所有的模块载入进去,再通过一个方法 __webpack_require__ 来引入并初始化所需要模块,有点像 nodejs 的做法,不需要自己去管模块的初始化顺序。但这里我想做得更好一点,不搞什么 xxx_require 的额外方法。怎么做?很简单,记录下模块间的依赖关系,写个拓扑排序将其转换成线性序列。
关于拓扑排序这里就不赘述,直接上百科😃
最终效果
不啰嗦了,直接上图!
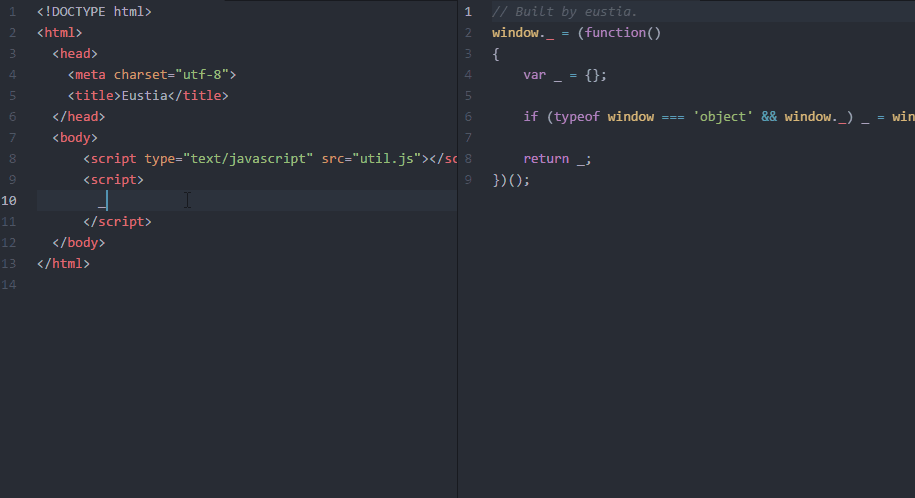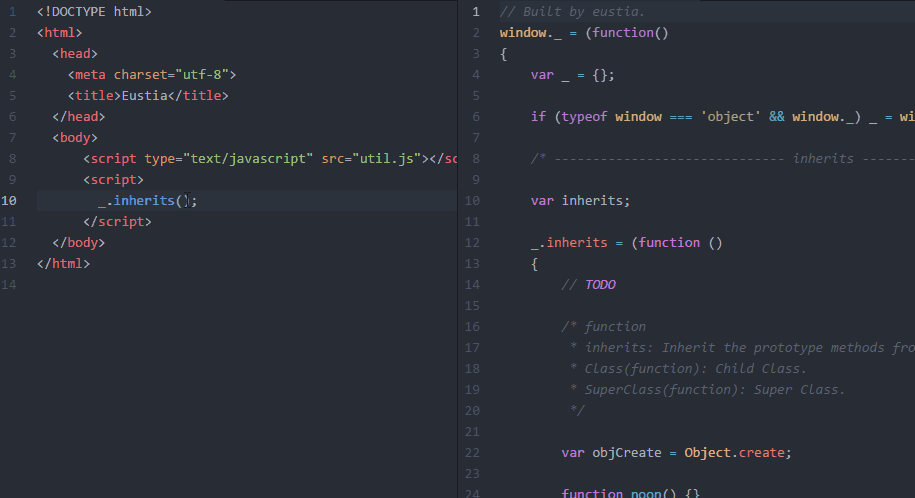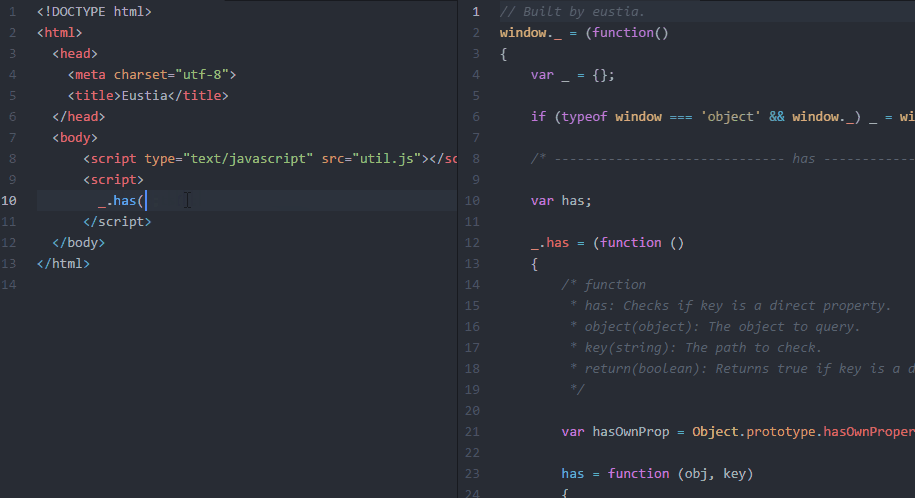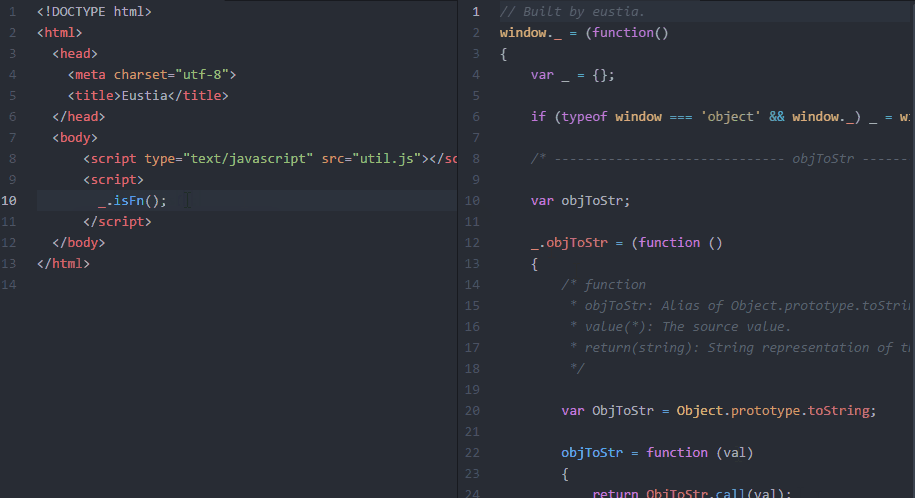
锦上添花
自动文档生成功能
加个简单的工具将注释轮换为文档,如下面的代码:
/* function
* inherits: Inherit the prototype methods from one constructor into another.
* Class(function): Child Class.
* SuperClass(function): Super Class.
*/
inherits = function (Class, SuperClass) { /*...*/ };可以直接生成文档: 
源代码转换
仿照 Webpack 加入各种源码转换工具的思路,我们可以用 es6 来编写代码模块,也可以自定义格式来实现简单的webcomponent,比如读书页面的通用组件是这么写的:
<require>template $ defaults</require>
<template id="containerTpl">
<div>A bunch of divs</div>
</template>
<script>
exports = function () {
/*...*/
};
</script>结语
在进行前端框架选型的时候,必须根据实际使用场景来决定。像读书这种页面,使用类似 vue 这种 mvvm 框架显然是不适合的。移动端在没有合适的框架库时,为节省代码量,提高页面加载速度,使用 vanilla js 也不失为一种好选择,只是要尽量杜绝重复代码的复制粘贴。就像 Live React: Hot Reloading with Time Travel at react-europe 2015 中演讲者讲到的,在开始项目前先完善项目相关的工具链,能够起到事半功倍的效果。可以使用工具自动化的事,尽量在项目开始时编写脚本来处理,而 Nodejs 是其中一种不错的选择。
最后,读书的前端基础库生成工具:https://github.com/liriliri/eustia,欢迎围观:)